
在開始設定不同資料源 Catalog 之前,必須先補充上一篇 config.properties裡被我略過的設定,也就是 Trino 鼎鼎有名的容錯機制 — Fault-tolerant。
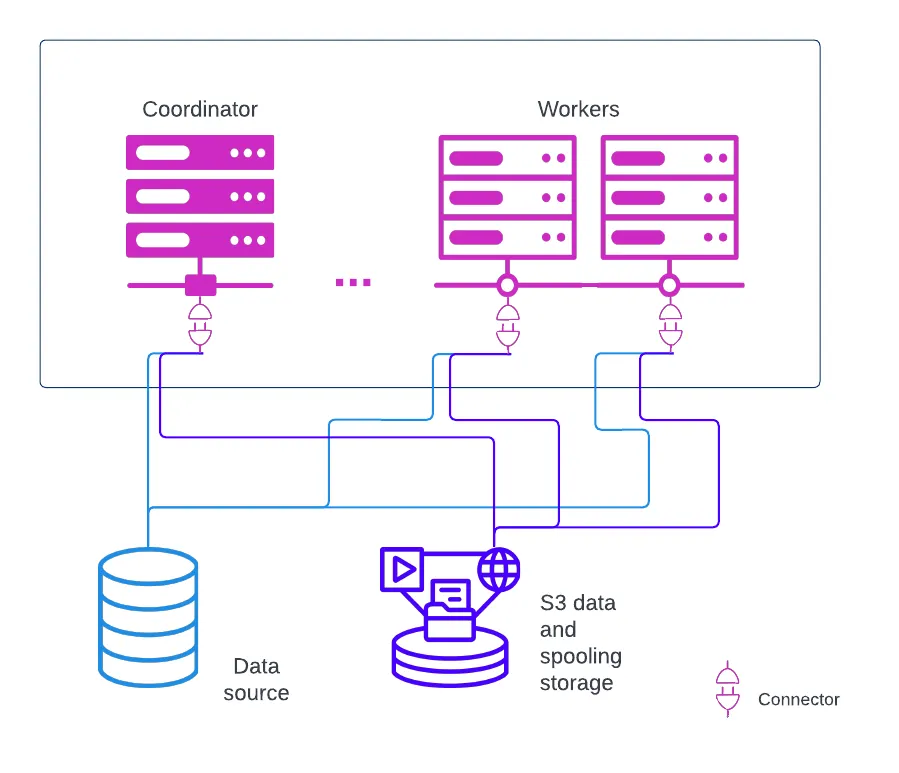
此機制將 Trino cluster 故障時執行到一半的查詢資料「捲」( spool ) 到外部儲存 ( 如AWS S3 ) 中,並分配給未陣亡的 worker 重試,避免讓前段查詢做白工,借用 Starburst 文檔的圖就是 深藍色線 的部分。
所以可知 Fault-tolerant 有兩個部分需要配置 :
重試政策 ( retry-policy ) :
告訴 Trino 在有 worker 壞掉時要怎麼進行查詢重試,分兩種方式:
retry-policy=QUERY 即整個查詢從頭再來一次,適合使用情境多為小於 32 MB 、低延遲的「小」查詢retry-policy=TASK 即只重跑失敗的 *task,適合使用情境多為大於 32 MB、需長時間處理的批次任務、「大」查詢暫存資料管理 ( exchange manager ) :
若重試政策為 Task,則須對 exchange manager 做配置,在 Trino cluster 成員們的 exchange-manager.properties 檔案裡,可以對失敗查詢暫存資料的存放方式、存放地點做設定,本文是以 AWS S3 當作例子 :
# exchange-manager.properties
exchange-manager.name=filesystem
exchange.base-directories=s3://sldatacenter-trino-fault-tolerant-development
exchange.s3.region=ap-southeast-1
exchange.s3.aws-access-key=${ENV:AWS_ACCESS_KEY_ID}
exchange.s3.aws-secret-key=${ENV:AWS_SECRET_ACCESS_KEY}
*task
Trino 將一個 SQL 查詢切成多個 stages,可能為讀取資料源、JOIN、AGGREGATION..等等
每個 stage 又會拆成多個 tasks,而 Trino worker 就是以 task 作為最小處理的任務單位
系列文明日《Trino 地端架設與調參 (四)》將帶你了解 Trino 如何透過設定 catalogs 來實現跨資料源查詢,並說明其中的配置重點與應用情境,讓你更有效率地整合多種數據來源。
My Linkedin: https://www.linkedin.com/in/benny0624/
My Medium: https://hndsmhsu.medium.com/

